 (читать Це из Эн по два)
лингвистических расстояний между ними (число сочетаний). Такие данные можно представить в виде таблицы, а можно в виде графов.
(читать Це из Эн по два)
лингвистических расстояний между ними (число сочетаний). Такие данные можно представить в виде таблицы, а можно в виде графов. Глава 4.
Один из результатов применения теории графов к исследованию доисторических процессов лингвистическими методами.
Свое повествование мы хотим продолжить применением всех тех данных, которые дают естественные науки: физика, математика, астрономия, география, и такие вспомогательные исторические дисциплины, как нумизматика и археология. Начинаем мы с того, что может дать царица наук - математика.
В последнее время было предпринято большое число попыток исследовать прошлое с помощью математики. Среди них были более или менее удачные методы с точки зрения корректности с математической точки зрения и информативности. Ниже мы изложим один историко-лингвистический метод, названный его автором методом графов (что касается автора данных строк, то он наверняка бы подобрал другое название, но он, как говорится, не хочет менять коней на переправе). Он был предложен филологом из города Львов Валентином Стецюком, а сам Стецюк основоположником этого метода называет филолога Иллича-Свитыча.
4.1. Сущность применяемого метода графов
Что касается математики, то материала, которые поддается обработке и позволяет извлекать ценные сведения, не так много. Один из немногих результатов, который может дать математика в области лингвистики - это некие результаты, касающиеся взаимоотношений народов, принадлежащих к разным языковым семьям.
Дальнейшее повествование данной главы будет целиком и полностью основано на работе украинского филолога Валентина Стецюка "Исследование доисторических этногенетических процессов в Восточной Европе" [115], выставленной Интернете на странице http://www.geocities.com/valentyn_ua
. (Эта же книга издана во Львове на украинском языке в 1999 году).Задача, которую себе поставил ее автор, состоит в следующем. На основании сегодняшних данных сравнительной филологии (количество общих языковых признаков в разных языках) по максимуму восстановить картину языкового развития человечества. В такой ситуации лучше всего слово предоставить самому автору, что мы и сделаем. (Можно, конечно, сделать некоторый филологический экскурс, но мы его опустим).
В 1998 году автором метода (Стецюком) было опубликовано описание исследований родственных взаимоотношений нескольких десятков языков, принадлежащих к разным языковым семьям. Исследование проводилось специальным математико-статистическим методом, который был разработан его автором после продолжительных поисков в конце 70-х - начале 80 годов и был назван графоаналитическим, поскольку именно графический анализ дал возможность устанавливать скрытые закономерности распределения общего лексического фонда родственных языков.
Описанные в работе исследования проводились на трех исторических уровнях развития языков. Сначала рассматривается родство между языками ностратической сверхсемьи (индоевропейская семья, алтайская, уральская, семитохамитская, картвельская и дравидская). На втором уровне исследовалась родство языков индоевропейской, тюркской, финно-угорской языковых семей, а на третьем - родство германских, иранских, славянских языков
.Методика состоит вот в чем.
Берется несколько языков (языковых семей). Эти языки разбиваются на пары. В этих парах считаются два параметра:
1.Количество тех языковых признаков, которые являются для них общими (пересечение множеств этих языков либо языковых семей), им присваивается буква Q
2.Для каждой из пар языков считаемся количество общих языковых признаков. Оно обозначается буквой M
(Примечание. Слово "лексический признак" имеет обобщенный характер и включает в себя не только лексику, но и фонетику, и грамматику. Более подробно - см. Иллича-Свитыча [061]..)
3.Выбирается некий масштабный коэффициент (для конкретности. Вообще-то, его можно и не выбирать и заведомо принять К=1)
4.По очень логичной формуле считается лингвистическое расстояние между языками для каждой из пар языков
L=K/(M-Q) (4.1.)
Таким образом, мы получаем следующую картину: мы имеем N языков и (читать Це из Эн по два)
лингвистических расстояний между ними (число сочетаний). Такие данные можно представить в виде таблицы, а можно в виде графов.
5.Для построения графов мы решаем следующую геометрическую задачу: нарисовать на плоскости N окружностей минимального радиуса таким образом, чтобы расстояния между точками, лежащими в кругах, которые они образуют, точно соответствовало расстоянию между исследуемыми объектами (языками или языковыми семьями)
Таким образом, мы на выходе получим следующую картину: N объектов исследования будут по плоскости представлены в виде кругов разного радиуса, а попарные геометрические расстояния на рисунке между ним будут точно соответствовать лингвистическим расстояниям L, вычисленным по формуле (4.1.) При этом радиус получившегося круга будет отображать некую погрешность метода.
Немного забегая вперед, автор этих строк скажет, что в работах Стецюка эта проблема была решена с некоторыми упрощениями, к тому же не всегда с надлежащими лингвистическими пояснениями (все-таки пионер, без шишек не обойтись), потому их было бы неплохо еще раз проделать на несколько более высоком уровне. Тем не менее, кое-что уже видно.
Полученный результат, помимо прочего, может содержать некую географическую и/или историческую интерпретацию. Автоматически среди данной группы исследуемых языков вырисуются языки "более древние" (будут лежать ближе к центру рисунка) и "более новые" (будут лежать ближе к краям рисунка). С точностью до некоторых поворотов плоскости рисунка могут еще вырисоваться основные ареалы расселения носителей данных языков (особенно ярко это может быть видно для родственных языков или диалектов одного языка).
Совершенно очевидно, что изобразить N кругов на плоскости, удовлетворяющим данным условиям - задач не из легких. Без некой методики, более совершенной, чем описал ее автор, не обойтись. О такой более совершенной методике автор книги попытается изложить свои представления.
4.2. Пару слов о более совершенной методике
Итак, есть N лингвистических объектов и лингвистических расстояний между ними. В общем случае, можно идти и от математики, и от лингвистики. Если идти от математики, то можно идти от дальних пар языков (с большим лингвистическим расстоянием) к ближним (с маленьким лингвистическим расстоянием) и от ближних пар языков к дальним.
По последнему методу выберем две языка с наибольшим расстоянием, разместим их на плоскости. Третий язык мы берем по критерию максимального суммарного лингвистического расстояния до первых двух, принцип наибольшего суммарного расстояния сохранится для выбора четвертого и последующих объектов исследования.
Следующим шагом разместим следующий, третий, язык на нужных расстояниях от первых двух (естественно, это возможно, если сумма расстояний не меньше расстояния между первыми двумя).
Сделаем это точно так же, как и при построении треугольника, циркулем проведя окружности нужных радиусов и первых двух точек и на пересечении поставив третью. Далее встанет задача размещения четвертого языка. Для этого мы, опять же, возьмем расстояния от каждой из трех точек до четвертой и проведем окружности нужных радиусов.
Здесь мы сразу сталкиваемся с той проблемой, что в общем случае, геометрического места пересечения трех окружностей может и не быть. Но, по всем законам математики, мы можем найти геометрическое место точек (в данном случае просто точку), откуда расстояния до всех трех окружностей
были бы одинаковы. В таком случае центр такой окружности был бы искомым месторасположением объекта, а радиус - характерной погрешностью метода.В качестве следующего шага мы займемся тем, что полученную погрешность - радиус вырисовавшегося круга - попытаемся равномерно распределить по всем четырем объектам исследования, в результате чего бы радиус окружности вокруг четвертого объекта бы уменьшился, а вокруг остальных троих бы возрос. Этого можно добиться небольшим варьирования параметров, легко достижимым компьютерными методами.
Дальше пойдет пятый язык. При этом мы проведем окружности лингвистических расстояний, центры каждой из которых будут находиться в центрах четырех получившихся кругов и радиусы которых будут равны сумме радиуса круга и лингвистического расстояния.
При нахождении центра пятого круга возникнет проблема, аналогичная той, которая возникла при рассмотрении четвертого языка: места точек, откуда от пятой до четырех остальных имеются нужные расстояния, может и не быть. Более того, в отличие от четвертой точки, вряд ли бы получилось найти то место на плоскости, откуда бы расстояния до трех окружностей были бы одинаковы.
Мы поступим аналогично тому, как в случае с четвертой: компьютерными методами найдем ту точку на плоскости, откуда сумма расстояний до этих четырех кругов будет минимальной. Такая точка и будет центром, а радиусом для конкретности мы возьмем среднее арифметическое расстояние от этой точки до каждой из окружностей. Теперь точно так же мы будем поступать для шестого, седьмого и т.д. последнего объекта исследования.
Пока это лишь планы. А сам автор метода поступил несколько иначе.
4.3. Применение данной методики к вопросу о взаимозависимости между ностратическими языковыми семьями
Итак, слово Стецюку:
"Начать историю этногенезиса целой группы народов надо было бы от самого происхождения человека, но этот вопрос вместе с вопросом о его прародине остается слишком дискуссионны. Поэтому начнем с менее дискуссионного вопроса происхождения ностратических языков. Единодушия среди ученых относительно реальности существования такой сверхсемьи языков нет, но, чтобы не углубляться ученые споры, проанализируем графоаналитическим методом уже собранные, обработанные, хотя и не до конца систематизированные результаты исследований В. М. Иллича-Свитыча [061]. Им были исследованы лексические, словообразовательные и морфологические сходства шести больших языковых семей Старого Света: алтайской, уральской, дравидской, индоевропейской, картвельской и семито-хамитской. Часть полученных в результате исследований данных была представлена в таблицах (морфологические признаки и лексика в количестве 147 позиций), и 286 лексических параллелей можно было найти в тексте".
Затем при проверке всего материала ... еще было добавлено 27 слов из уральских и 8 из алтайских языков [035]).
В результате оказалось, что из 433 всего количества признаков 34 являются общими (к ним мы еще вернемся), а остальное составили 255 единиц из уральских, также 255 - из алтайских, 253 единицы из индоевропейских, 240 - из семито-хамитских, 189 - из дравидских и 139 из картвельских. было подсчитано количество общих признаков в парах языков, но при этом не учитывалось разная весомость морфологических признаков и лексических единиц, хотя это совсем разные категории. Однако количественная оценка этой весомости все равно была бы субъективной, и мы будем надеяться, что морфологические признаки распределились среди языков более или менее равномерно. Подсчеты дали результаты, представленные в таблице 4-1:
Таблица 4-1. Количество общих признаков между семьями языков
|
алтайские - уральские |
167 |
уральские - картвельские |
66 |
|
алтайские - индоевропейские |
153 |
индоевропейские - семито- хамитские |
147 |
|
алтайские - семито-хамитские |
149 |
индоевропейские - дравидские |
108 |
|
алтайские - дравидские |
109 |
индоевропейские - картвельские |
70 |
|
алтайские - картвельские |
84 |
семито- хамитские - дравидские |
110 |
|
уральские - индоевропейские |
151 |
семито- хамитские - картвельские |
86 |
|
уральские - семито- хамитские |
136 |
Дравидские - картвельские |
54 |
|
уральские - дравидские |
134 |
|
|
Проанализировав полученные данные, нельзя сразу сказать о какой-либо определенной их закономерности, однако можно заметить, что больше всего общих слов имеют между собой алтайские, уральские, семито-хамитские и индоевропейские. Сначала нужно выбрать коэффициент пропорциональности, а далее пересчитать количества общих признаков в расстояния между ареалами языков. Выбор значения коэффициента определяется размерами листа, на котором строится схема. В соответствии с нашими данными подходит значение K=1000. Тогда расстояния между ареалами отдельных языков будут иметь значения, представленные в таблице 4-2:
Таблица 4-2. Расстояния между центрами языковых семей на схеме
|
алтайские - уральские |
6.0 |
уральские - картвельские |
15.2 |
|
алтайские - индоевропейские |
6.5 |
индоевропейские - семито- хамитские |
6.8 |
|
алтайские - семито-хамитские |
6.7 |
индоевропейские - дравидские |
9.3 |
|
алтайские - дравидские |
9.2 |
индоевропейские - картвельские |
14.3 |
|
алтайские - картвельские |
11.9 |
семито- хамитские - дравидские |
9.1 |
|
уральские - индоевропейские |
6.6 |
семито- хамитские - картвельские |
11.6 |
|
уральские - семито- хамитские |
7.4 |
Дравидские - картвельские |
18.5 |
|
уральские - дравидские |
7.5 |
|
|
Построение схемы родства идет в несколько итераций. Сначала по двум координатам для каждого языка находится одна точка, которая определяет приблизительное положение ее ареала, а в следующих итерациях идет уточнение расположения всех ареалов языков. В принципе можно начать с любого языка, но сразу неизвестно, в какую сторону пойдет построение, и схема может выйти за пределы листа. Потому удобнее всего начать построение с пары языков, которые имеет наибольшее количество общих признаков. В нашем случае это алтайские и уральские языки (эти проблемы предлагается решить методом, описанным в предыдущем разделе
- ВП).Следовательно, сначала произвольно расположим где-то в центре листу отрезок AB длиной 6 см, который соответствует количеству общих признаков в этой паре (см. Рис. 4-1). Концы этого отрезка определяют место точек для алтайских и уральских. Далее на базе этого отрезка строятся точки для индоевропейских и семито-хамитских языков. Начнем с семито-хамитских, поскольку эти языки имеют больше общих признаков с картвельским и дравидскими, чем индоевропейский. В соответствии с количеством общих признаков точка семито-хамитских языков должна находиться на расстоянии 6,7 см от точки алтайских и на расстоянии 7,4 см от точки языков. Циркулем с соответствующим раствором делаем две засечки и на их пересечении находим точку семито-хамитских языков. Таких точек может
быть две - слева и справа от базы. Выбор одной из этих двух возможных точек определяет окончательный вид схемы, которая может иметь два варианте, зеркальные по отношению друг к другу.Выберем точку, которая лежит ближе к центру. Теперь у нас три точки - A, B, C, и мы переходим к построению точки D (индоевропейские языки). Ее положение определим тоже на базе отрезка AB. Она должна быть на расстоянии 6,5 см от точки A и на расстоянии 6,6 см от точки B. Циркулем делаем две соответствующие засечки в сторону, противоположную от точки C и получаем точку D. (Располагать ее возле точки C нельзя, поскольку в этом случае семито-хамитские и индоевропейские языки должны были бы иметь значительно больше общих признаков, чем они имеют на самом деле). Точку E для дравидских языков строим на базе BC, поскольку именно семито-хамитские и уральские языки имеют более всего общих признаков с дравидскими. Итак, эта точка располагается на расстоянии 7,5 см от точки уральских языков и на расстоянии 9,1 см от точки семито-хамитских языков в направлении от центра схемы, иначе она ляжет возле точки алтайских языков, почему противоречит количество общих признаков между ними. Аналогично строится точка F для картвельских языков, только в этом случае на базе AC. Первая итерация закончена -
получена скелетная схема родства ностратических языков. Их ареалы должны быть где-то в районе полученных точек A, B, C, D, E, F.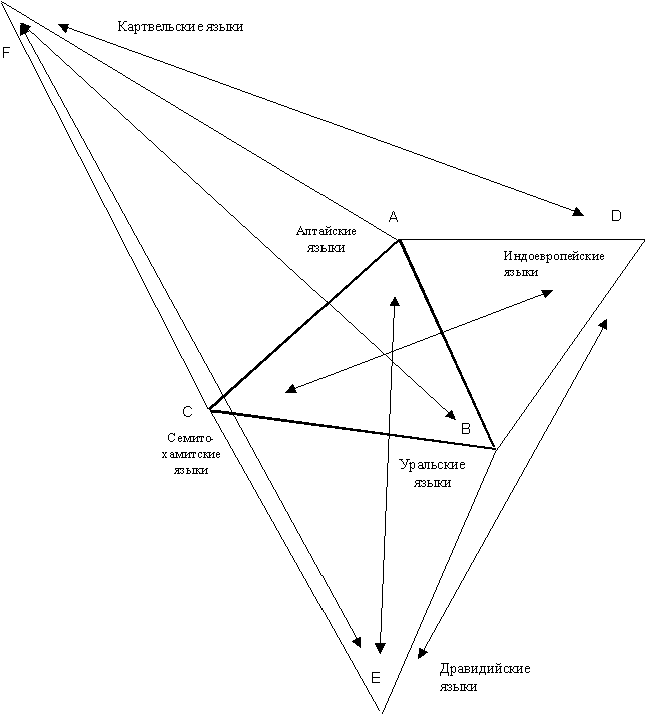
Рисунок 4-1. Первая итерация построения схемы родства ностратических языков
Вторая итерация дает возможность уточнить и проверить правильность расположения ареалов. При этом точки отдельных языков строят по другим координатам. Например, точка D строилась по двум координатам, которыми были отрезки AD и BD. Теперь мы можем использовать в качестве
координат, скажем, те же самые отрезки в других сочетаниях - с отрезками, которые отвечают расстоянию ареала индоевропейских языков от ареала дравидских, семито-хамитских и картвельских. Потом можно взять еще и другие возможные сочетания. В целом мы должны были бы получить 10 точек, которые бы нам очертили ареал индоевропейского языка. При этом каждый раз при выборе одного из двух возможных вариантов мы должны выбирать тот, при котором новая точка ложится ближе к уже построенным.В данной версии описание второй и третьей итераций опускается.
Окончательно схема семейных отношений ностратических языков принимает вид, показанный на рисунке 4-2.
Полученная таким образом схема является одним из двух зеркальных вариантов, из которых выбрано именно этот по той причине, что именно для него удалось найти место на географической карте. Здесь нужно только обратить внимание, что при поисках соответствующего места на географической карте для получаемых схем родства нужно каждый раз подбирать новый коэффициент пропорциональности в соответствии с масштабом карты, то есть строить геометрически подобную схему другого размера в соответствии с размерами ареалов на карте.
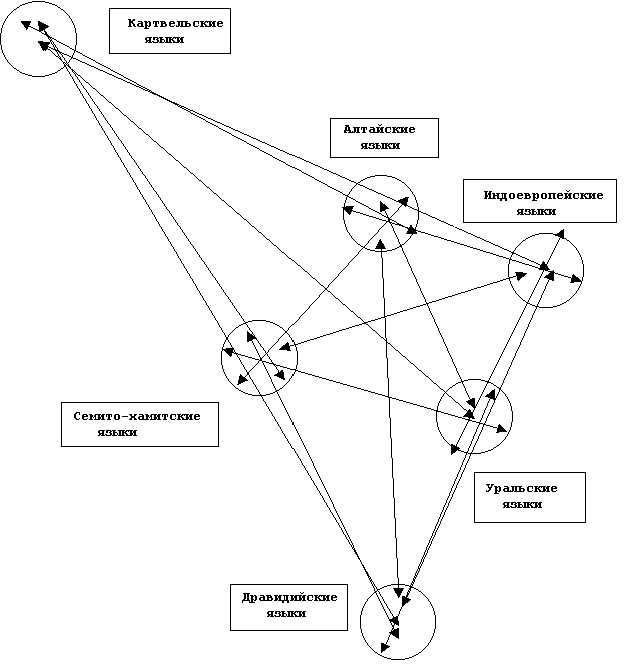
Рисунок 4-2.
Схема родственных отношений ностратических языковЕще раз обратим внимание на то, что деформации схемы при этом не производится".
Прервем немного автора метода. Обратим внимание на одно удивительное обстоятельство: дравидские, картвельские и индоевропейские языки лежат в вершинах получившегося треугольника, а вот семитские, уральские и алтайские - на сторонах. То есть очень грубо виден теоретически возможной ностратический праязык: он должен представлять нечто среднее между семитскими, уральскими и алтайскими. В качестве небольшого примечания прибавим, что Морозов, как у автора сложилось впечатление, призывал не видеть разницы между тюрками и венграми. Или, по крайней мере, не придавать этой разнице большое значение. (Иллич-Свитыч в своих характеристиках взаимозависимость между этими языками уже описывал неким числом, следовательно, работа по сравнению этих языков была проделана не очень недавно - ВП).
Глядя на рисунок 4-2, мы можем найти одну его интересную интерпретацию. А именно мы можем смело семьи можем подразделить на ранние - семитскую, уральскую и алтайскую, и поздние - дравидскую, картвельскую и индоевропейскую. Полученное обстоятельство немаловажно при анализе генезиса тех или иных народов и поиске ответов на те или иные вопросы, зачастую очень болезненные
.....Вновь Стецюк.
Пока же попытаемся определить время, когда носители шести ностратических языков начали расселяться со своих прародительских мест поселений. Сначала вспомним, что Т.В.Гамкрелидзе и В.В.Иванов относят первое диалектное членение индоевропейских языков, когда возникают первые диалекты, из которых позже развились анатолийские языки, не позднее IV тыс. до о.э. ([051], 861). И уже затем индоевропейцы, по их мнению, двинулись в Европу вокруг Каспийского моря и где-то по дороге от них отделилась индоиранская группа".
Здесь, наверное, придется прервать интереснейший рассказ Валентина. Еще раз проконстатируем основной его вывод: все ностратические народы разошлись от Арарата. Кто раньше, кто позже. Есть те, кто пораньше. Есть те, кто попозже. Есть местности, жители которых четко помнят, в том числе на уровне легенд и мифов о праистории, что они - коренные жители. Есть местности, где помнят, что откуда-то пришли. Есть местности, где жители вообще ничего не помнят. Есть места на карте, где представители конкретного рассматриваемого народа были первыми. Есть места на карте, куда представителей тех или иных народов пускали. Есть те, куда их не пускали.
Очень интересно построить их географическое распределение на карте мира. Опять должны получиться вариации на араратские темы.
Вот то самое, что нам смогла рассказать о тех глубоких доисторических временах теория графов. Будем надеяться, что это хоть что-то.
Что касается географии - то мы к ней будем возвращаться неоднократно. Что касается астрономии - то затмения вроде бы все сходятся, да и с календарями проблем немного.
Что касается археологии и нумизматики... Автор проявит здесь скромность и предоставит чудесную возможность специалистам по данной теме подробно высказаться на страницах других книг. Это на многовариантность повлияет по привычной схеме "данная археологическая находка (группа находок) работает на одну версию, на другую, на третью, на все вместе".
Тем не менее в области монетной он позволит себе две цитатыОдну - из сайта о татаро-монгольском иге:
"Например, один из ученых глубокомысленно отмечал: "На многих монетах русских князей стоят непонятные черточки и точки". А несколькими строчками ниже делал из своего наблюдения обескураживающий вывод, это - древнерусское письмо. И мало того, давал перевод "непонятным черточкам и знакам", подгоняя его под известное: "Владимир на столе и се его сребро..." Академик Б. Рыбаков тоже внес свою неоценимую лепту переводами надписей с "древнерусских" пряслиц. Правда, в отличие от вышеназванного "переводчика", академик, как обычно, реконструировал текст, подрисовывая "пропавшие" буквы".
Вот так мы историю любим.
И еще одно следствие из этого. Очень часто энтузиасты арийского, т.е. индоевропейской древности ищут арийскую древность и очень мало что находят. А вот древность семитскую, которой в поисках можно найти очень много, они отвергают. Не будем тему продолжать - она слишком многогранна и риторична. Однако факт есть факт.
И другую - из Девидсона-Льюмена [006], перевод автора. "На обратной стороне монеты Карла Великого было ясно написано: MAGOG". (Здесь сразу же автор книги оговорится, что за неимением места он не будет здесь рассматривать все сложности, связанные с Карлом Великим, с точки зрения многовариантности, так как это тема для отдельного исследования). А о ГОГах и МАГОГах мы уже немного знаем.
Еще просто очень хочется рассказать о московском филологе-энтузиасте, кандидате филологических наук Николае Николаевиче Вашкевиче. Он в нескольких своих книгах (например, "Системные языки мозга" [047] , М. 1996, издательство не указано) убедительно доказал, что старые следы из языков семитских групп (например, из арабского) очень хорошо сохранились во многих арийских языках (например, в русском и английском) в виде пословиц и поговорок, не вполне логичных и не имеющих объяснения на первый взгляд.
Мысль Вашкевича очень интересно продолжить в несколько другом направлении. Как известно, в свое время у филологов была весьма популярна одна в известной степени пикантная тема - тема группы слов, которые в русском языке прочно закрепились как неприличные, которые тем самым прочно заняли место ненормативной лексики, и смысл этих же слов в других языках. Например, мат. Насколько автору данных строк известно, те слова, которые в русском языке действительно считаются неприличными, в других языках, в частности, ранних имеют вполне легальное существование.
Приведем короткий пример с арабским: по-арабски корреспондент, журналист будет мурасилутун. В русском языке есть считаемое не вполне приличным слово "мура" (в смысле "чушь", "ерунда"). То есть с точки зрения арабского
менталитета (менталитета "ранних" языков) выходит, что речь идет о любом сообщении, сведениях, а с точки зрения русского менталитета - что речь идет о сведениях заведомо неинтересных.
4.4. Небольшое обобщение метода граф на процесс развития человечества с точки зрения лингвистики.
Если говорить в общем случае, сейчас восстановление картины генезиса человечества с точки зрения лингвистики становится интересной счетной задачей, в которой важен вклад не только лингвистики, но и математики.
Вновь посмотрим на рисунок 4-1. Смело скажем, что этот рисунок содержит очень интересную информацию о развитии человечества с языковой точки зрения. Рисунок 4-2 - это схема с ярко выраженным центром и окраинами. Зададимся вопросом: могут ли эти самые центр и окраины быть интерпретированы с точки зрения языкового генезиса человечества?
Если да (давайте проявим оптимизм), то возможно два теоретически возможных направления процесса: от центра к окраинам и от окраин к центру.
То есть центробежный вариант (рисунок 4-3),
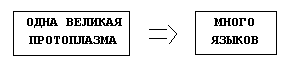
Рисунок 4-3. Центробежный вариант развития языков.
при котором из одного общего праязыка (или, как можно выразиться более корректно, языковой протоплазмы), разные языки развиваются в сторону увеличения лингвистического расстояния между ними, то есть имеет место тенденция к обособлению все большего и большего числа языков.
И центростремительный вариант, который описывается схемой
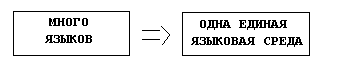
Рисунок 4-4. Центростремительный вариант развития языков.
и при реализации которой множество мелких диалектов и языков стремится к максимальному уменьшению и формированию единого общего языка.
На примере развития растительного мира мы знаем совершенно четко, что наиболее вероятный был первый вариант. Некий аналог на примере развития садовых культур: в процессе развития садоводства из одного-двух изначально существующих прасортов дикого яблока развились (точнее, сами не развились, но садоводы их вывели) много садовых сортов. При этом райское яблоко вполне удовлетворяет требования "яблока хоть какого-то", а более поздние сорта удовлетворяют более высокие вкусовые требования.
Итак, из рисунков ясно с большим предпочтением мы отдаем перевес центробежному варианту. А раз уж так, раз уж наиболее предпочтительным выглядит этот самый центробежный вариант, то тезис о ранних и поздних группах мы можем считать доказанным.
А из рисунка 4-2 мы можем ясно интерпретировать три из шести группы, которые поближе к центру рисунка, как ранние и три из шести групп как поздние. А раз уж так, так мы от абстрактных схем перейдем к оценочной хронологии и скажем, что арабский возник, видимо, раньше картвельского, венгерский раньше тамильского, а татарский и турецкий раньше русского. (Внимание! Мы первый раз за всю книгу употребили слово "татарский" чисто в современном этническом смысле). И если бы были какие-то взаимоотношения между русским и татарским, как между двумя соседними народами, то они бы развивались лишь в одном направлении: русский оказывался бы как язык условно более поздний в роли языка более высокоразвитого и вытесняющего, а татарский, как язык более ранний - в роли вытесняемого. (В качестве примечательного: филологи-энтузиасты в средневековом русском ловят значительное число тюркизмов. Смотрите хотя бы Сулейменова [117]. Или записки Афанасия Никитина, как указывает Фоменко в [124]).
Результат. Все ностратические языковые семьи теоретически представимы в виде ранних (семито-хамитская, уральская, алтайская